(CVPR2023) Generalized Relation Modeling for Transformer Tracking
[CVPR’2023] - Generalized Relation Modeling for Transformer Tracking
论文地址:Generalized Relation Modeling for Transformer Tracking
代码地址:https://github.com/Little-Podi/GRM
贡献
1. Introduction
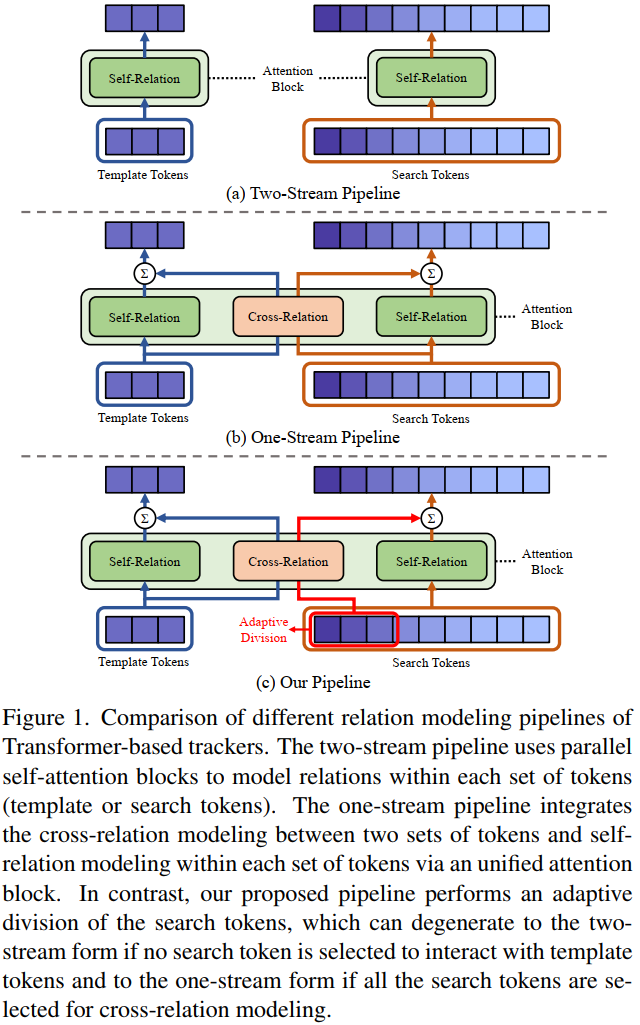
过去主流的跟踪方法基本都是是two-stream trackers,分别对template和search region进行特征提取,然后用各种fashion进行cross-relation。
最近,one-stream pipeline被提出联合特征提取和relations过程。如图1(b)。
最近的方法证明让search region 和template 尽可能的相互关联(global cross-relation modeling)是对 target-specific 的特征生成有益的。
但是本文认为search region中并不是所有的部分都需要强制与template关联。因为由于跟踪中的cropping strategy裁剪策略,也就是template一般裁剪2倍目标大小,而搜索区域裁剪4倍目标大小。这意味无论是模板帧还是搜索区域都有一大部分是背景,其中可能存在相似目标。这会导致干扰。
- 搜索区域中的背景token可能会与模板建立交叉关系,最终可能对定位造成混淆。
- 模板区域中的token与全局搜索区域建立交叉关系,可能会导致模板特征的质量下降
所以本文提出generalized relation modeling method来自适应地选择适当的搜索标记来与模板交互。把template和 search tokens分为三类,template token一类,search tokens两类。只有适合cross-relation modeling的search token会与template token交互。
用个lightweight prediction module来划分search token,自适应的决定哪些search token适合cross-relation modeling。但是有两个问题:1)不同token类别的独立relation modeling很难并行训练。2)离散token 类别不可微,无法学习。因此本文使用attention masking策略来统一将独立注意力操作为一个操作。引入Gumbel-softmax技术来是的离散token类别可微。
- 我们提出了 Transformer 跟踪器的关系建模的广义公式,它将输入token分为三类,并使模板和搜索区域之间的交互更加灵活。
- 为了实现广义关系建模,我们设计了一个token划分模块来自适应地对输入token进行分类 。 引入注意力mask策略和 Gumbel-Softmax 技术来促进所提出模块的并行计算和端到端学习。
- 我们进行了大量的实验和分析来验证我们方法的有效性。 所提出的 GRM 在六个具有挑战性的视觉跟踪基准上表现出了出色的结果。
2. Related Works
2.1. Visual Tracking Paradigms
2.2. Trackers with Dynamic Designs
3. Method
3.1. Preliminary
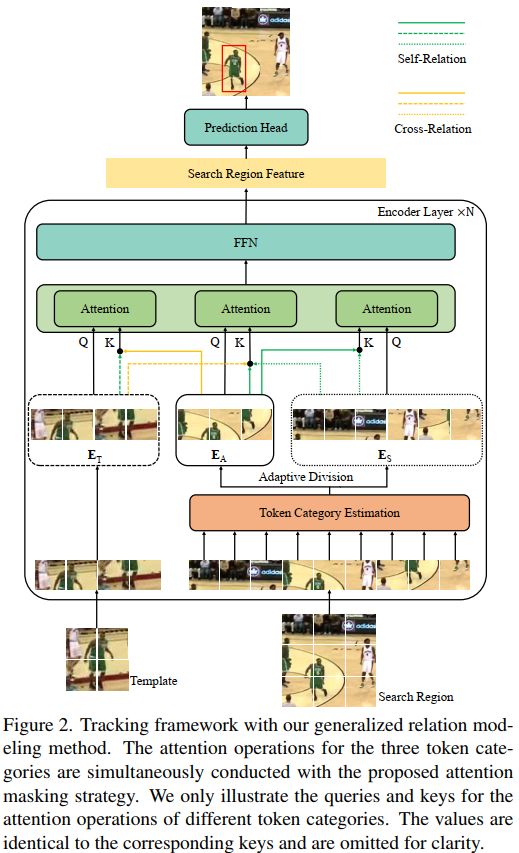
开始和one-stream的方法一样,把template和search region 进行划分成patch,并patch embedding,所有token作为序列送入encoder,encoder layer的操作如下
3.2. Generalized Relation Modeling
如图,把输入token

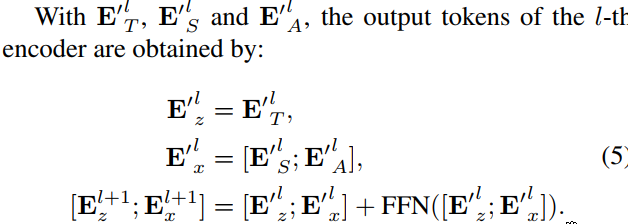
当搜索token全被划为
3.3. Adaptive Token Division
search tokens的分类网络,每个encoder layer一个learnable prediction module。将最大池化后的模板特征按通道concat到搜索特征中,然后送入MLP。
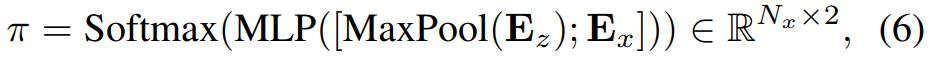
首先并行训练的问题。受DynamicViT启发,应用attention masking 策略。
首先把 probabilities
定义两个one-hot 向量
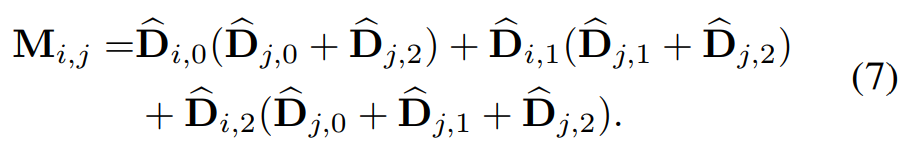
表示token i是否可以根据关系建模规则聚合token j的信息,对应于公式2,3,4。通过计算注意掩码的Hadamard积和所有输入标记的注意权重矩阵,我们可以将三种注意操作合并为具有相同功能的单个操作。
然后,由于search token的离散类别不可微。应用Gumbel-Softmax技术,通过重新参数化技巧从具有类概率π的分类分布中绘制样本:
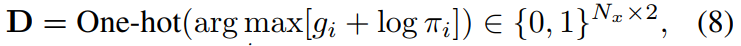
其中g ~ Gumbel(0,1),argmax运算被softmax运算取代为连续可微的近似:
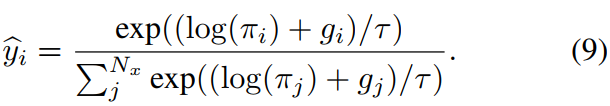
在训练阶段,使用Eq.(8)采样的离散分类D来划分前向的搜索令牌,并从Eq.(9)中的连续Gumbel-Softmax近似计算后向的梯度。torch里面也有直接实现的torch.nn.functional.gumbel_softmax(),Gumbel softmax trick。
3.4. Target Prediction Head
用了OSTrack的center head, 一个2D特征图来预测目标的位置,它由三个卷积分支组成,分别负责中心分类、偏移回归和大小回归。中心分类分支输出一个分数图,其中每个分数表示目标中心位于相应位置的置信度。利用偏移回归分支对离散化误差进行补偿。大小回归分支预测目标的高度和宽度。选取中心分数图中置信度最高的位置作为目标位置,并对其进行回归
