(CVPR2023) SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
[CVPR’2023] - SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
论文地址::SeqTrack: Sequence to Sequence Learning for Visual Object Tracking
代码地址:https://github.com/microsoft/VideoX
贡献
先前的Siamese trackers和transformer trackers需要head networks(classification and regression heads),这篇文章提出了一个简单的encoder-decoder transformer 结构来直接得到输出结果。
采用了 STARK 和 Pix2Seq 的思想。
1. Introduction
本文认为现存的跟踪方法通常采用被称为divide-and-conquer策略(分治策略),也就是把跟踪任务分解成多个子任务(目标尺寸估计和中心点定位等)。这种分治策略虽然获得了优越的性能,但是存在两点限制:
- 每个子任务需要特定的head网络,这导致了复杂的框架结构。
- 每个head网络要求不同的loss functions,例如 cross-entropy loss,
loss和 GIoU loss。这需要多个超参,训练困难。
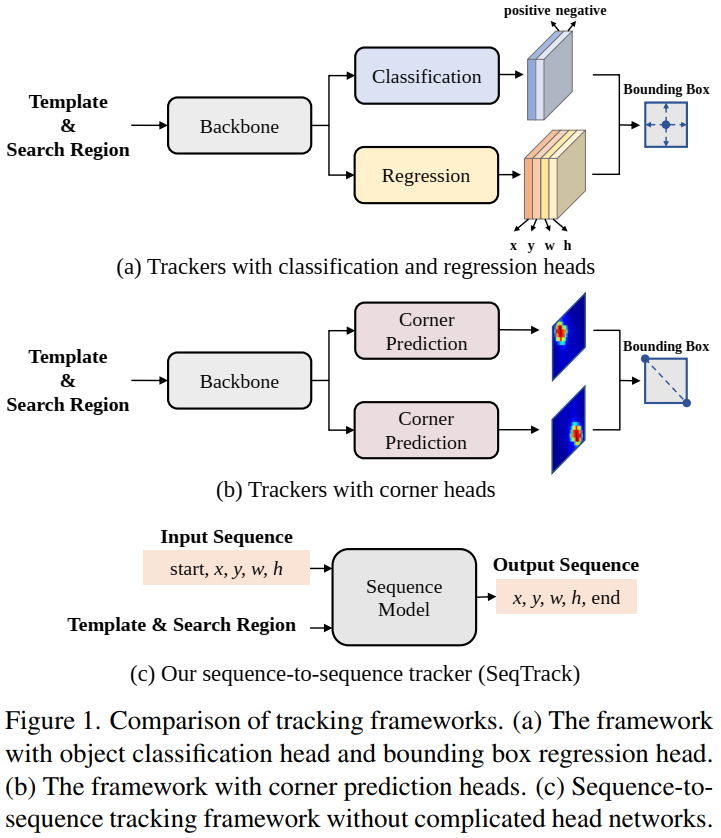
本文提出Sequence-to-sequence Tracking (SeqTrack) 。把跟踪作为一个sequence生成任务。将bounding box的四个值
2. Related Work
Visual Tracking.
Sequence Learning. 本篇文章SeqTrack的基本思路其实来源于ICLR2022那篇Hinton的Pix2Seq。区别在于三点:
1)Pix2Seq 是以目标corner坐标和目标类别来设置sequence,SeqTrack是以目标中心点坐标和目标尺寸为sequence。
2)结构不同。Pix2Seq 是resnet作为backbone,后面跟encoder-decoder transformer。SeqTrack 更简洁,只有一个encoder-decoder transformer,其中ViT作为encoder来提取特征,causal transformer blocks作为decoder来生成sequence。
3)任务不同。Pix2Seq 是检测,SeqTrack是跟踪。
3. Method
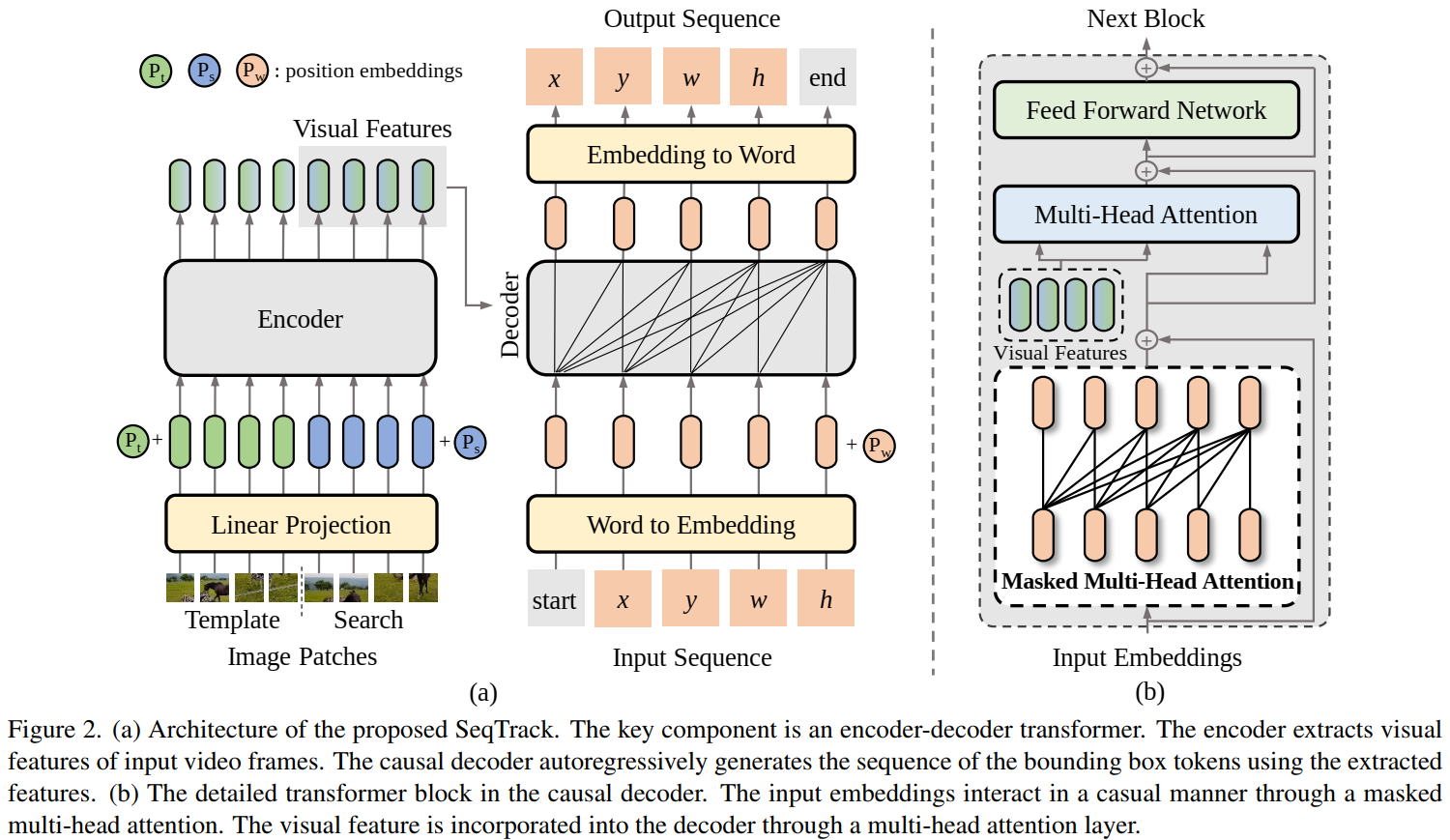
3.1. Overview
- 目标的bounding box 被转化成discrete token 序列(
)。 - encoder 提取目标特征,decoder以自回归的形式生成bounding box token 序列。
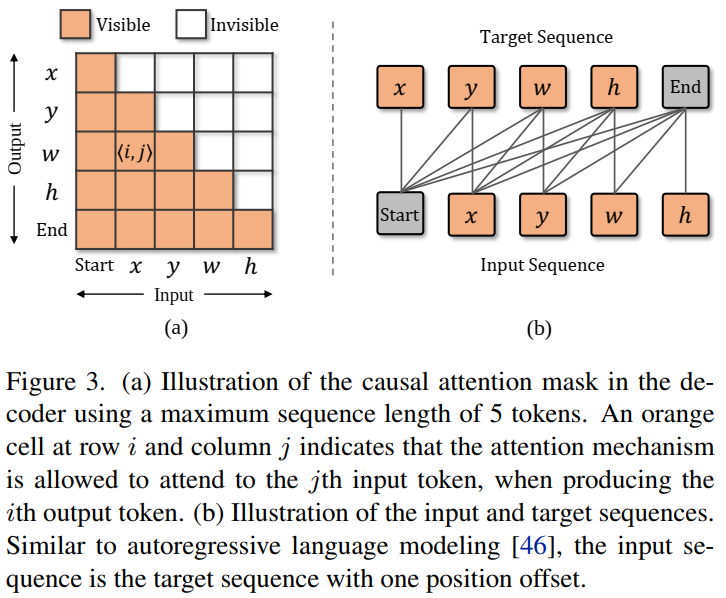
- causal attention mask 添加到self-attention 模块
- 除了四个坐标token,额外添加两个特殊token:start 和 end。start token表示开始生成,end表示生成完成。训练阶段,decoder输入为
[start,x,y,w,h],目标是[x,y,w,h,end] - 在每一步中,都会生成一个新的bounding box token,并将其附加到输入序列中以生成下一个。
3.2. Image and Sequence Representation
Image Representation。 encoder 输入包括一个template image
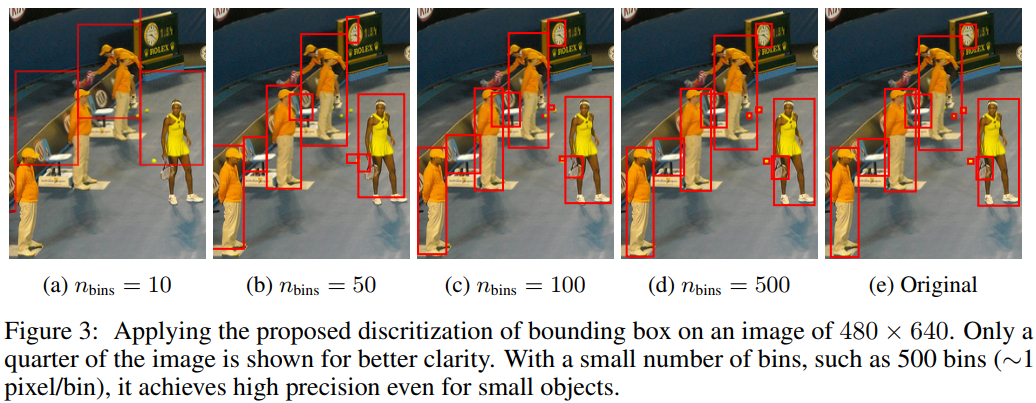
Sequence Representation。把bounding box转换成discrete tokens。每个连续坐标被均匀地离散成[start,x,y,w,h],目标是 [x,y,w,h,end]。最后把输出的embedding映射会words。
这里其实就是Pix2Seq的sequence construction过程,将图片高和宽分成
3.3. Model Architecture
Encoder:与标准ViT差不多。区别在于(1)没有class token。(2)linear projection 被添加在最后一层以对齐encoder和decoder的维度。提取完visual features后,只有search feature被送给decoder。
Decoder:每个transformer block 包含a masked multi-head attention, a multi-head attention, and a feed forward network (FFN)。attention mask限制在位置i的输出embedding只关注小于i位置的输入embedding。
3.4. Training and Inference
Training:使用交叉熵损失最大化基于前子序列和输入视频帧的目标token的对数似然。
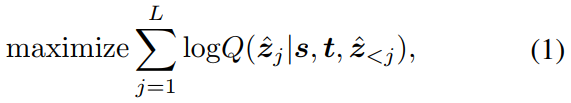
Q是softmax probability。s是search image,t是template。
Inference:编码器感知模板图像和后续视频帧中的搜索区域。decoder的初始输入是start token。对于每个token,模型根据最大似然从词汇表V中采样
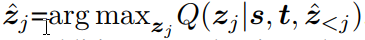
引入了online template update和window penalty。
3.5. Prior Knowledge Integration
Online Update。除了初始模板,引入了一个动态模板。使用生成的token的可能性likelihood来自动选择可靠的动态模板。如果平均得分大于特定的阈值
Window Penalty. 经验证明,连续两帧之间的像素位移是相对较小的。为了惩罚较大的位移,我们在在线推理过程中引入了一种新的窗口惩罚策略。具体地说,目标对象在前一帧中的位置对应于当前搜索区域的中心点。当前搜索区域中中心点的离散坐标为
4. Experiments
4.1. Implementation Details
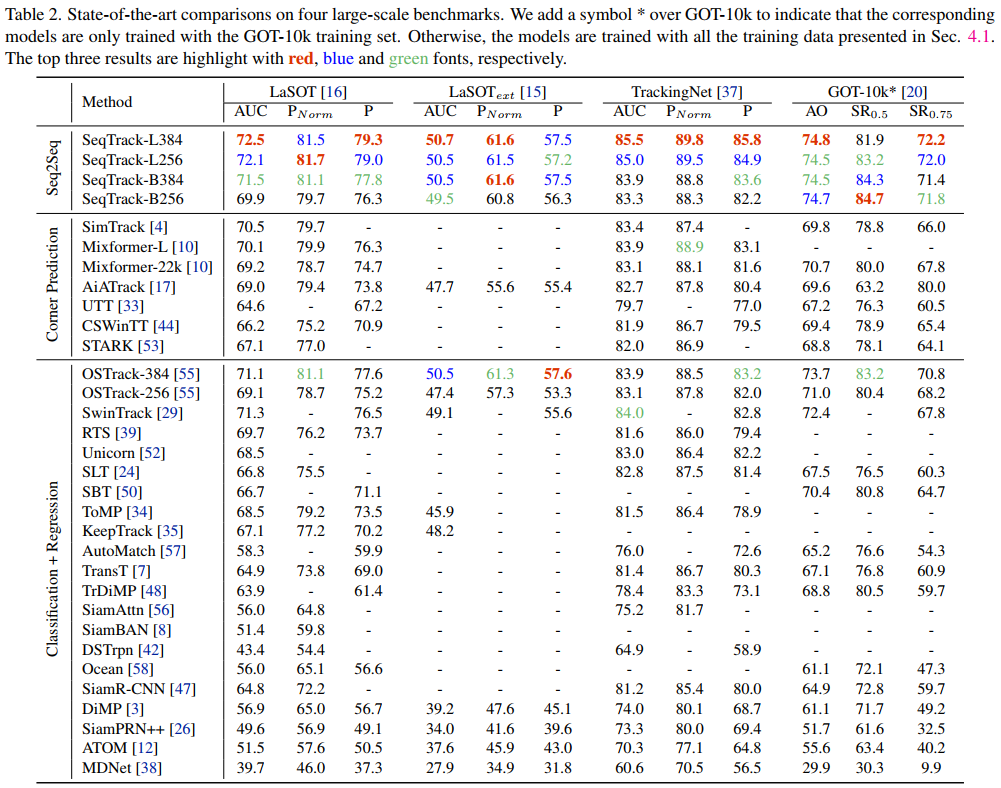
4.2. State-of-the-Art Comparisons
LaSOT,TrackingNet,GOT-10k
VOT2020,with Alpha-Refine to predict masks

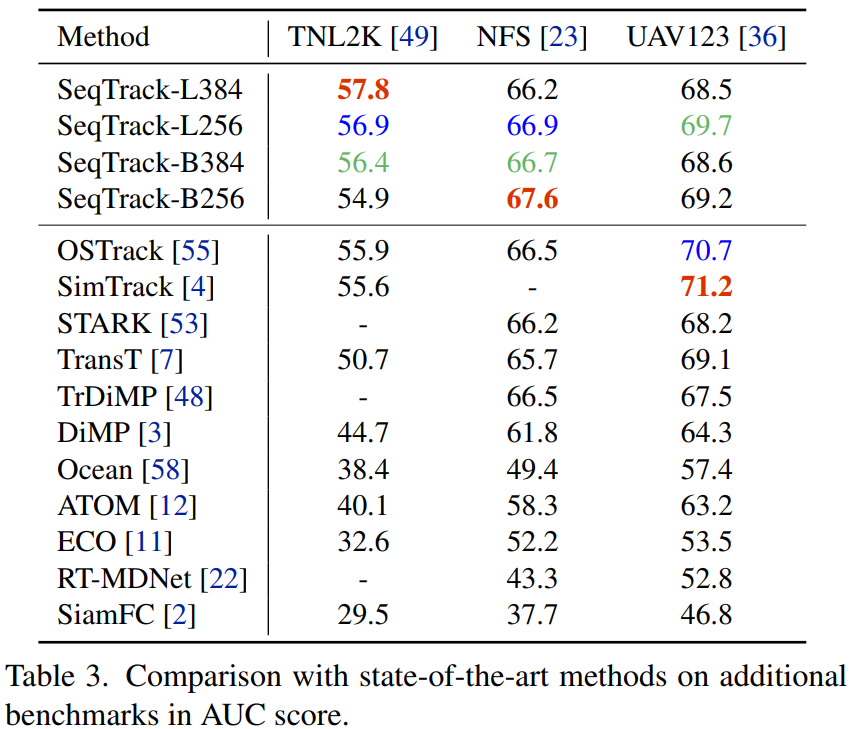
TNL2K,NFS,UAV123: